Don’t Rate Teaching Schools Based on Student Test Scores, Study Warns

;)
Untangle Your Mind!
Sign up for our free newsletter and start your day with in-depth reporting on the latest topics in education.
This is the latest article in The 74’s ongoing ‘Big Picture’ series, bringing American education into sharper focus through new research and data. Go Deeper: See our full series.
How do you rate a teacher prep program?
About 2,000 of them exist across the United States — mostly degree-focused departments within colleges and universities, but also “alternative” programs operated by Teach for America or for-profit companies like Kaplan. They assign coursework, give aspiring teachers experience in the classroom, and send their graduates into schools. So how do we know which ones do the best job of equipping future educators with the skills they need?
According to research published in the journal Education Next, there’s one clear way not to do it: using student test scores. Reviewing studies that examined teaching programs in six locations, University of Texas professor Paul T. von Hippel writes that rankings based on “value added” models — complex measurements of growth on standardized test performance — essentially spit out random results.
The finding is noteworthy, since the federal government has spent the past few years wrestling with the question of how to improve teacher quality. In the waning days of the Obama administration, the Department of Education issued a mandate for all states to classify their teacher preparation programs using certain metrics of student outcomes, and particularly student value-added scores. Last year, the Senate voted 59–40 to block the rule, with a large number of Democratic defectors from states that President Trump won in 2016.
Teachers unions applauded the reversal, saying that drawing conclusions from test scores would penalize teachers who work in disadvantaged schools (and the programs that those teachers attended). Still, some 21 states and the District of Columbia have announced that they would “collect and publicly report data that connect teachers’ student growth data to their preparation programs.”
That’s a bad mistake, says von Hippel. With co-author Laura Bellows, he writes that the original DOE rule and state-level efforts to replicate it are wrongheaded efforts to glean information from unreliable sources.
For one thing, there are very few studies pointing to meaningful differences between different teacher prep programs — whether at a university education department, at a for-profit enterprise, or within the umbrella of a municipal “teaching fellowship” — based on student test scores. Von Hippel notes that neither the DOE officials who drafted the short-lived regulation, nor the union voices that vociferously opposed it, cited existing research to make their cases.
In fact, he writes, there are so many possible variables in measuring teaching programs (the strength of an individual class of future teachers, the schools to which they are later assigned, and the makeup of their own students, to name just a few) that it is nearly impossible to assess the success or failure of a program based on student test scores.
“The errors we make in estimating program differences are often larger than the differences we are trying to estimate,” von Hippel and Bellows write. “With rare exceptions, we cannot use student test scores to say whether a given program’s teachers are significantly better or worse than average.”
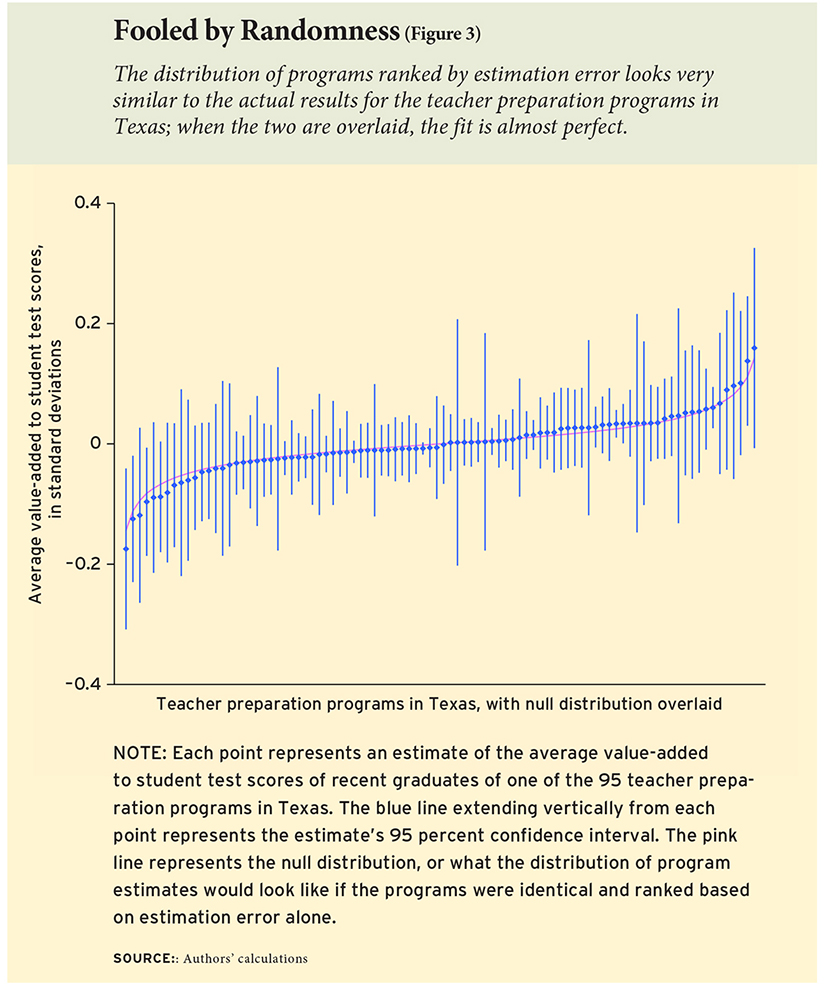
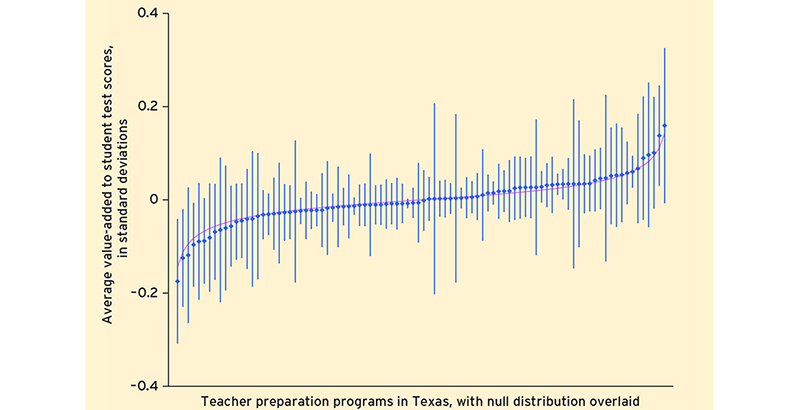
To illustrate the point, von Hippel charts the value-added scores of students taught by graduates of Texas’s roughly 100 teaching programs, sorted from lowest to highest. He then overlays another distribution of the programs — this one counting all of them as identical, except for random estimation errors. The two charts look almost completely the same.
He then examines previous studies that focused on teacher preparation in Florida, Louisiana, Missouri, Texas, Washington State, and New York City, reanalyzing using the same statistical methods.
“In every state,” he writes, “the differences between most programs were minuscule. Having a teacher from one program or another typically changed student test scores by just .01 to .03 standard deviations, or 1 to 3 percent of the average score gap between poor and non-poor children.”
Too little hard information, lost amid far too much statistical noise, makes program rankings like the ones recommended by the DOE next to useless, von Hippel and Bellows conclude. But that doesn’t mean we should ignore the question of how teachers are prepared for the classroom, especially since a significant body of research indicates that teacher quality is the single most important ingredient to student success.
Principal evaluations are one possible alternative, but they are also biased in ways that are unfair to teachers of disadvantaged students. Teachers can also be asked to rate the programs they graduated from, though that presents the opportunity for bias to creep in as well.
The best existing proposal, the authors argue, is to measure programs based on the percentage of their graduates who are hired and retained as teachers. Given the relatively large number of teaching school graduates who never take classroom roles, or who leave the profession within a few years, programs’ records of placing their graduates in schools long-term may be the best reflection of their success.
Go Deeper: This is part of The 74’s ongoing ‘Big Picture’ series, bringing American education into sharper focus through the newest research, data, and surveys. See our full series.
Get stories like these delivered straight to your inbox. Sign up for The 74 Newsletter
